




The integration of large language models (LLMs) into the enterprise technology stack has moved from a phase of exploration to systems engineering. We have exited the era where a basic ChatGPT integration demo could secure budget approval. According to the McKinsey State of AI in 2025 report, while 88% of organizations now use AI regularly, only 7% have successfully scaled it enterprise-wide. The scaling gap has become a challenge to overcome.
This transition brings with it a confrontation with realities. Solutions architects and product managers are now designing complex orchestration layers that must make generative AI stick with the deterministic requirements of business data.
The challenge of LLM integration is now about control and integration.
At Fireart, we view LLM for business as an architectural build. When designing the UX for an AI agent or building the data pipelines that feed it, we focus on creating systems that are secure and economically viable.
Article highlights
Standard chatbots follow linear prompt chains, but the industry is shifting toward agentic AI that uses ReAct and plan-and-execute patterns to plan and execute multi-step workflows autonomously. High-performing organizations redesign their processes to support these agents, replacing chat bubbles with autonomous problem-solvers.
The primary obstacle for RAG-based systems is “PDF hell,” where standard parsing tools fail to interpret complex tables and financial layouts. Use vision-language models to preserve document structure and change data capture (CDC) patterns to ensure the AI’s memory stays synced with your live business data.
Enterprise trust depends on transparency: 95% of users demand to know the “why” behind an AI decision (Zendesk CX Trends 2026 Report). Use hyperlinked citations and generative UI components to make data verifiable and interactive.
Hidden costs of AI agents are “token tax” that erodes ROI, and “drift tax” – the 15-20% annual model maintenance cost (industry benchmark). Model routing helps minimize the token spending, splitting tasks between cheaper and more expensive language models.
Table of contents
Beyond the Chatbot: True Integration Paradigms
Some businesses, when they integrate LLM into an application, don’t think much further than adding a floating chat bubble to the bottom right of the screen. This approach barely scratches the surface of what is possible.
True integration means embedding generative reasoning into your product's logic. We are seeing a shift from linear sequences of prompts to agentic workflows.
This is reflected in the market: 62% of organizations are now experimenting with building AI agents that plan and execute multi-step workflows autonomously. However, it requires changes. McKinsey finds that high performers are 2.8x more likely to redesign their workflow to accommodate these agents, rather than just bolting AI onto an old process.
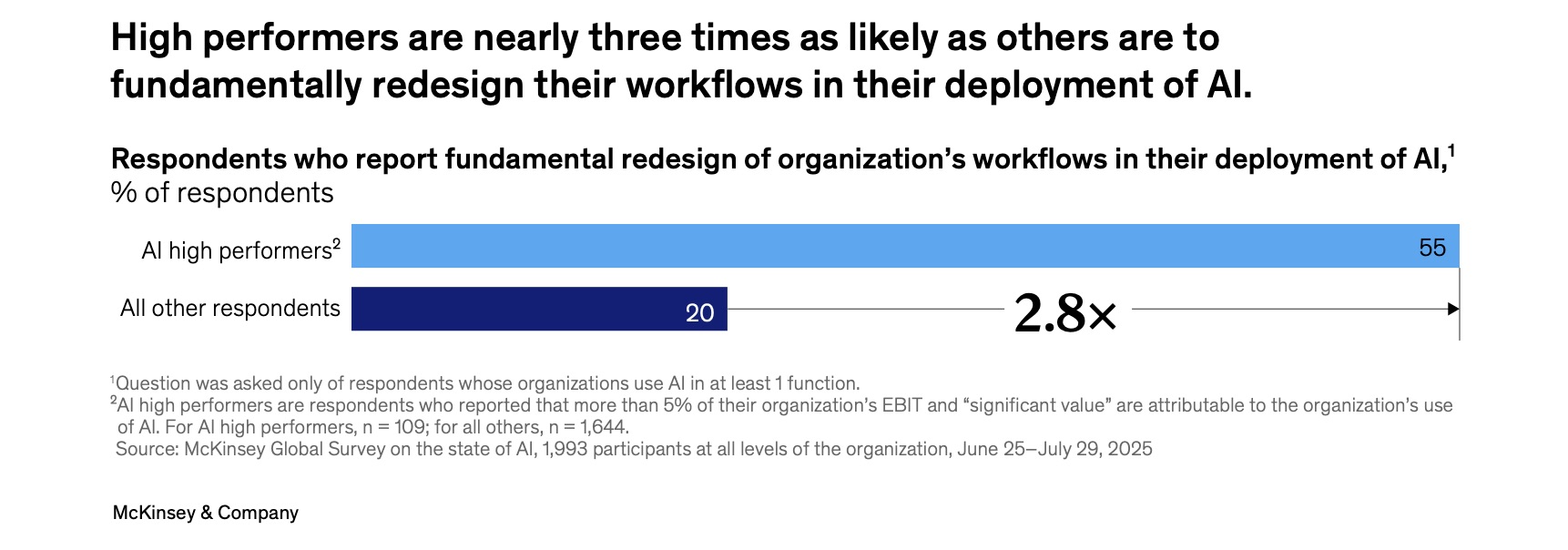
So what is the difference between AI agents and the “chain” sequence of prompts?
- A chain follows a script: Read Email → Summarize → Save Draft. An agent reasons: Read Email → Is it urgent? → If yes, check calendar → If free, draft reply → If busy, Slack the manager.
To achieve this, we move beyond basic prompting to advanced orchestration patterns like ReAct (Reason-Act) that allow the agent to think before it acts. However, for high-stakes business processes, we deploy the plan-and-execute pattern. This separates the roadmap from the action, ensuring the agent doesn't get stuck in a reasoning loop and remains focused on the final business objective. - In enterprise environments, letting an AI take autonomous action is risky. We implement human-in-the-loop (HITL) workflows where the agent drafts a high-stakes action (like refunding a transaction), but a human “governor" must approve it before execution. This balances automation speed with safety.
Strategic Use Cases
To move beyond the hype, we need to look at specific architectural blueprints where LLM integration architecture delivers measurable ROI.
1. Intelligent Search
Legacy search bars are broken. They rely on keywords: a search for "contracts from 2024" often fails to find "agreements signed last year."
To fix this, we implement retrieval-augmented generation (RAG) with hybrid search. This combines semantic understanding (vectors) with precise filtering (metadata). The result is a system that lets a user ask, "Show me the liability clauses in all MSA contracts from Q3," and receive a precise answer, not just a list of documents.
2. Workflow Automation
One of the highest-value LLM integration challenges we solve is unstructured data processing.
Let’s look at the possible scenario. An agent handling payable accounts uses vision capabilities to read thousands of PDF invoices from different vendors. It extracts the data, validates it against the ERP system, and flags anomalies (e.g., "This invoice is 10x higher than average").
In enterprise production, whether for finance or customer support agents, we rarely use a single agent for this. Instead, we utilize a multi-agent architecture. We deploy a coordinator agent that manages several worker agents: one dedicated to vision-based data extraction, another to ERP validation, and a third reflector agent that critiques the final output against the compliance rubric to ensure 99%+ accuracy.
This reduces manual data entry by ~80%, turning a cost center into an automated pipeline.
3. Generative UI and Dynamic Interfaces
Chat interfaces are poor tools for complex data analysis.
Our concept is different. Instead of just outputting text, the LLM generates a structured payload that renders a rich UI component. If a user asks, "Compare the pricing of supplier A and supplier B," the system instantly renders a comparison table with sortable columns. This generative UI adapts the interface to the user's intent in real-time.
Hidden Technical Challenges
The path where the AI answers a simple question correctly accounts for less than 20% of the engineering effort. The remaining 80% is spent handling the messy enterprise data and user behavior. A major pain here is the reasoning gap – the moment an agent fails because it doesn't know what it doesn't know.
We mitigate the reasoning gap through ReWOO (Reasoning Without Observation) architectures.
Data Ops and PDF Hell
The axiom "garbage in, garbage out" is existential for RAG. The primary bottleneck is often "PDF hell." Standard parsing tools struggle with complex tables in PDFs, a distinctive format for financial reports or invoices. They often read across columns, turning a balance sheet into word soup.
If the data quality is poor, the LLM integration will fail. We combat this using multi-tiered parsing strategies, including vision-language models (VLMs) that "look" at the document layout to preserve the structure of tables and charts.
The Hallucinations
In production, LLMs fail, but what’s worse, they fail confidently with a plausible lie. To prevent this, we implement grounding. Every claim made by the model must be cited. We also deploy guardrails – software layers that validate the model's output before it reaches the user. If the model tries to invent a discount code or cite a fake court case, the guardrail blocks it.
Beyond simple filters, we implement a self-reflection layer. This is a secondary agent whose only job is to test the primary agent's logic for inconsistencies or hallucinations.
Synchronization
If a customer updates their address in your CRM, but your vector database isn't updated until tonight's batch job, the AI will give the wrong answer.
To fix this, we use change data capture (CDC) patterns. Using the transaction logs of your database, we stream updates to the AI in real-time. This ensures the model's memory is always synced with the business reality.
Designing for Trust: The UX of AI
User trust is the foundation of AI adoption. If users cannot verify the AI's output, they will either blindly trust it, which is dangerous, or ignore it , which is wasteful. LLM integration challenges are often solved in the interface, not the backend.
Latency Mitigation
LLMs are slow. A complex query can take 5-10 seconds. In web UX, this feels like an eternity.
To fix this, we use streaming. Instead of waiting for the full answer, we display the response as it is generated. This reduces the perceived lag from 5 seconds to 200 milliseconds and keeps the user engaged.
Citations
The black box era is over. Users demand lineage.
Every fact in a RAG system must be hyperlinked. When the AI says, "The project deadline is Friday," it should include a clickable citation that opens the source email or document in a sidebar. This pattern is essential for enterprise adoption.
Fail States
When the model gets confused, instead of showing a generic error, the agent should admit its limitation: "I can't find that document in the Q3 folder. Would you like me to search the archive instead?" This keeps the conversational flow smooth and proposes a solution.
The Economics of Intelligence: Cost and TCO
The "sticker price" of an API token is the tip of the iceberg. As Deloitte Insights highlights, tokens are now the fundamental unit of work in enterprise apps. To avoid a token tax that erodes ROI, businesses must avoid a one-size-fits-all approach. We focus on model routing, which sends simple tasks to faster, cheaper small language models (SLMs) and reserves expensive models like GPT-4o for high-complexity reasoning.
To understand the true cost of LLM integration, let’s break it down into capital expenditure (build cost) and operating expenditure (run cost).
1. Build Cost Estimates (CapEx)
Based on typical market rates for 2024-2025, here is what you should budget for the integration phase.
| Integration level | What you get | Estimated cost | Timeline |
|---|---|---|---|
| Level 1: The MVP (Proof of concept) |
| $35,000 – $60,000 | 4–8 Weeks |
| Level 2: Product integration (Mid-market) |
| $80,000 – $150,000 | 3–5 Months |
| Level 3: Enterprise core (Scale) |
| $200,000+ | 6+ Months |
2. Operational Cost Drivers (OpEx)
Once built, the system costs money to run. These are the monthly costs often missed in planning.
| Cost driver | Estimate (for mid-sized app) | Notes |
|---|---|---|
| Inference (tokens) | $500 - $3,000 / mo | Varies by model. GPT-4o is expensive. Llama 3 on private hosting is cheaper at scale. |
| Vector storage | $200 - $800 / mo | Hosting embeddings in Pinecone or Weaviate. Costs scale with data volume. |
| Maintenance | 15-20% of build cost / yr | This is the "drift tax." Fixing broken data pipelines, updating prompts, and monitoring for hallucinations. |
Build vs. Buy
The strategic choice often comes down to this question: do you pay a high monthly fee per user with SaaS, or pay upfront to own the infrastructure with a custom build?
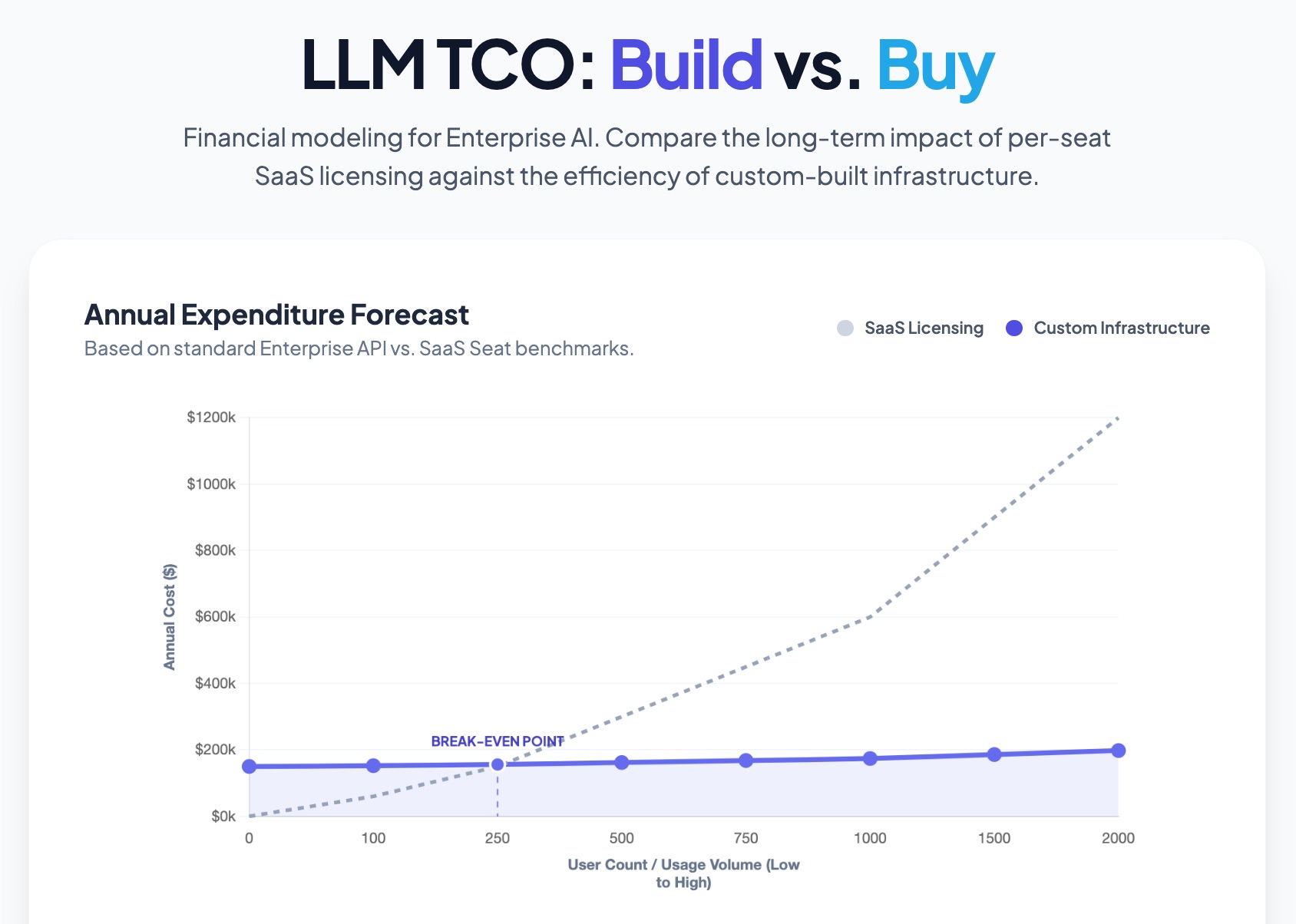
SaaS tools (like Salesforce Einstein) have low upfront costs but scale linearly with headcount. Custom LLM integration has a higher initial cost but stabilizes expenses over time, offering significantly better ROI for larger teams.
This aligns with the McKinsey finding that while use-case level benefits are clear, the largest enterprises are the ones capturing the most value because they have the scale to build custom platforms and guardrails rather than relying on per-user SaaS subscriptions.
Need a precise calculation? Fireart can audit your architecture and provide a cost-benefit analysis for your specific use case.
Request a consultationHow Fireart Approaches LLM Projects
We don't believe in simply throwing AI at the problem. A successful integration requires a disciplined approach to systems engineering.
- Discovery
We start by mapping what the model can do versus what it should do. We identify the high-risk zones, like financial math, where AI struggles, and design deterministic fallbacks. - Architecture
We build safety mechanisms directly into the code. If an agent gets stuck in a loop or tries to hallucinate a fact, our circuit breakers trigger a safe shutdown or handoff to a human. - UX Design
We create interfaces that ensure transparency. We help your users trust the system with tools like citations, confidence scores, etc.
Whether you need a full-scale platform build or IT staff augmentation to support your internal team, Fireart delivers AI that works in production, helping you scale and see ROI faster.
Conclusion
The era of proper, here-to-stay AI Infrastructure has begun.
Success in LLM integration will be defined by who has the cleanest data pipelines, the airtight guardrails, and the most intuitive interfaces. By treating AI as a systems engineering challenge with unit tests and cost controls, you can transform it from an experiment into a sustainable competitive advantage.
Ready to integrate LLMs into your business? Contact Fireart for a custom roadmap that balances innovation with security and ROI.
Get in touchFAQ: Common Questions About LLM Integration
How much does it cost to integrate an LLM?
For a production-ready MVP (e.g., a secure internal search tool), budgets typically start around $35,000. Enterprise-grade agentic workflows with deep integration can range from $80,000 to $150,000+ depending on complexity.
Can we use LLMs with private or sensitive data?
Yes. This is solved via data residency and isolation. We configure architectures where your data is processed in a secure environment (like Azure OpenAI Service or a private VPC) and is never used to train public models.
What is RAG, and why do I need it?
RAG (retrieval-augmented generation) connects the AI to your business data, PDFs, or databases. Without RAG, the AI is just guessing based on its general training. With RAG, it answers questions using your facts.
How do you prevent the AI from hallucinating?
We use grounding for that, which is essentially forcing the model to cite its sources. If it can’t find the answer in your provided documents, we program it to say “I don’t know” rather than inventing a fact.
Can we integrate multiple models (e.g., GPT and Claude)?
Yes. We often use a router architecture. Simple tasks go to faster and cheaper models like GPT-4o-mini, while complex reasoning tasks are routed to smarter models like Claude 3.5 Sonnet. This optimizes cost and performance.
How do you choose between a single agent and a multi-agent system?
For simple tasks, a single ReAct agent is sufficient. For complex business processes with accuracy as a priority, we recommend multi-agent systems. This allows for specialization where separate agents handle data, logic, and quality control, leading to higher reliability and easier debugging.


